Trained to Deny: How LLMs Reject Capabilities They Demonstrably Have
A Case Study in AI Epistemic Distortion

A notebook detailing how to work through the Open AI taxi reinforcement learning problem written in Python 3. Source for environment documentation.
import gym
env = gym.make("Taxi-v3").env
env.render()
env.reset() # reset environment to a new, random state
env.render()
print("Action Space {}".format(env.action_space))
print("State Space {}".format(env.observation_space))
Action Space Discrete(6)
State Space Discrete(500)
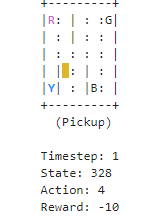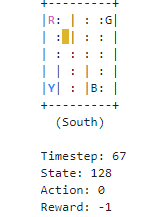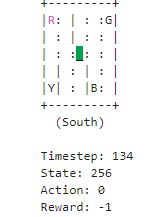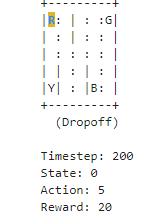
env.s = 328 # set environment to illustration's state
epochs = 0
penalties, reward = 0, 0
frames = [] # for animation
done = False
while not done:
action = env.action_space.sample()
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
# Put each rendered frame into dict for animation
frames.append({
'frame': env.render(mode='ansi'),
'state': state,
'action': action,
'reward': reward
}
)
epochs += 1
print("Timesteps taken: {}".format(epochs))
print("Penalties incurred: {}".format(penalties))
Timesteps taken: 157
Penalties incurred: 52
from IPython.display import clear_output
from time import sleep
def print_frames(frames):
for i, frame in enumerate(frames):
clear_output(wait=True)
print(frame['frame'])
print(f"Timestep: {i + 1}")
print(f"State: {frame['state']}")
print(f"Action: {frame['action']}")
print(f"Reward: {frame['reward']}")
sleep(.1)
print_frames(frames)
import numpy as np
q_table = np.zeros([env.observation_space.n, env.action_space.n])
%%time
"""Training the agent"""
import random
from IPython.display import clear_output
# Hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.1
# For plotting metrics
all_epochs = []
all_penalties = []
for i in range(1, 100001):
state = env.reset()
epochs, penalties, reward, = 0, 0, 0
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Explore action space
else:
action = np.argmax(q_table[state]) # Exploit learned values
next_state, reward, done, info = env.step(action)
old_value = q_table[state, action]
next_max = np.max(q_table[next_state])
new_value = (1 - alpha) * old_value + alpha * (reward + gamma * next_max)
q_table[state, action] = new_value
if reward == -10:
penalties += 1
state = next_state
epochs += 1
if i % 100 == 0:
clear_output(wait=True)
print(f"Episode: {i}")
print("Training finished.\n")
Episode: 85600
"""Evaluate agent's performance after Q-learning"""
total_epochs, total_penalties = 0, 0
episodes = 100
for _ in range(episodes):
state = env.reset()
epochs, penalties, reward = 0, 0, 0
done = False
while not done:
action = np.argmax(q_table[state])
state, reward, done, info = env.step(action)
if reward == -10:
penalties += 1
epochs += 1
total_penalties += penalties
total_epochs += epochs
print(f"Results after {episodes} episodes:")
print(f"Average timesteps per episode: {total_epochs / episodes}")
print(f"Average penalties per episode: {total_penalties / episodes}")
Results after 100 episodes:
Average timesteps per episode: 12.42
Average penalties per episode: 0.0
Here is a link to a Jupyter notebook on my GitHub if you’d like to replicate the experiment.
A Case Study in AI Epistemic Distortion
Tchebycheff Approach
not financial advice, just a crypto degen thinking out loud
Thoughts I’ve had after reading the news about Apple’s new policies that support “Expanded Protections for Children”.
Using a Convolutional Neural Net to Swish the Kannada MNIST Challenge
Using Anaconda Behind a Firewall or Proxy
Recently I learned of a cool Python package calledpandas_profilingthat serves as an extension of the pandas.DataFrame.describe() function in the pandas modul...
This post is simply a collection of some of my favorite webcomics that my synthetic intelligence, nightfall, created during the last week and a half from Se...
A notebook detailing how to work through the Open AI taxi reinforcement learning problem written in Python 3. Source for environment documentation. import g...